PREDIKSI SGP ATAU BOCORAN SGP ANGKA MAIN HARI INI, PREDIKSI SINGAPURA JITU | BOCORAN TOGEL SGP SINGAPURA. Hari ini anda tidak salah situs karena mwdug memberikan bocoran sgp. Tujuannya menang di akhir artinya kita bet main togel singapore itu untuk menang bukan malah kalah. Angka main sgp hari ini di ambil dari team prediktor terpercaya, Tetapi permainan togel sgp banyak teman yang tidak mengerti bahwa pasaran togel singapore adalah yang terbaik.
Kita tidak bisa melakukan metode pasang nomor singapura sedikit line, harus banyak line. Kenapa? karena semakin banyak angka sgp yang kalian beli maka kemenangan akan semakin di depan mata. Hilangkan pikiran menang banyak tetapi berfikirkan bagaimana bisa untung.

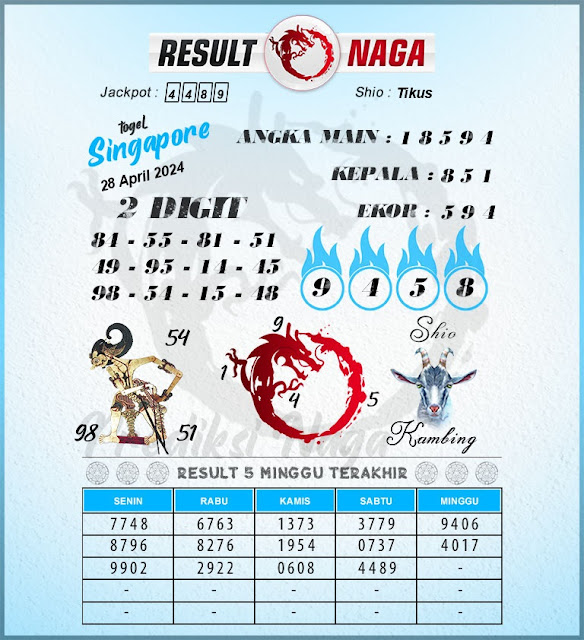
Inilah Prediksi master sgp hari ini sebagi berikut :
Contents
MASTER JITU BOCORAN SGP HARI INI
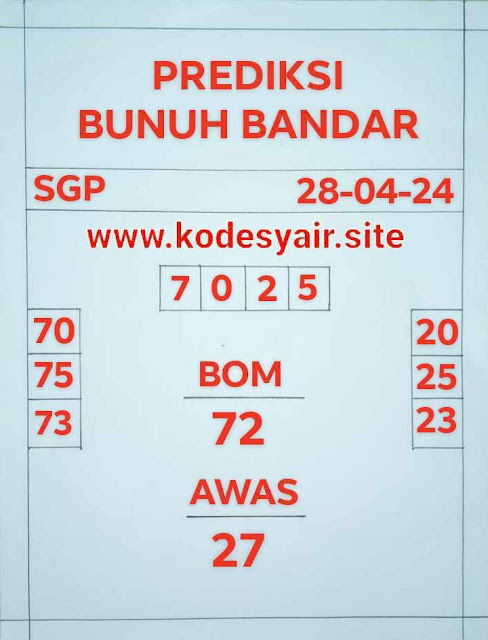
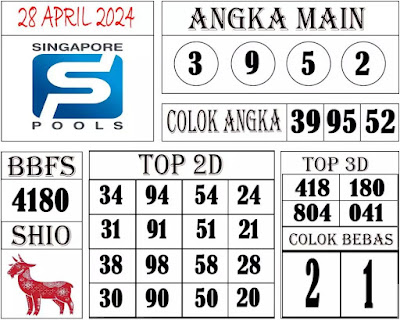
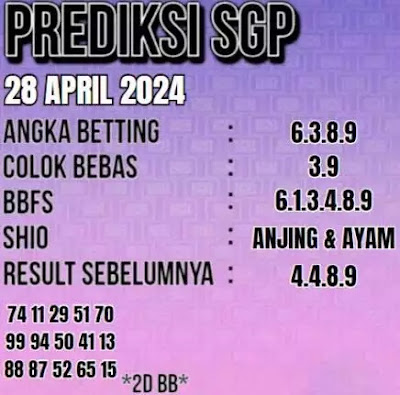
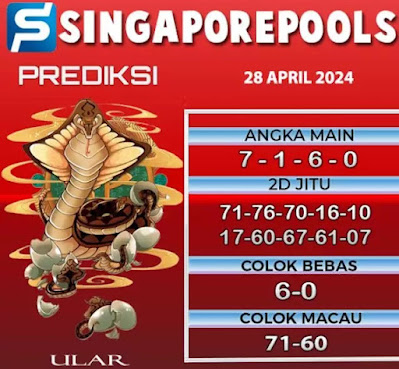
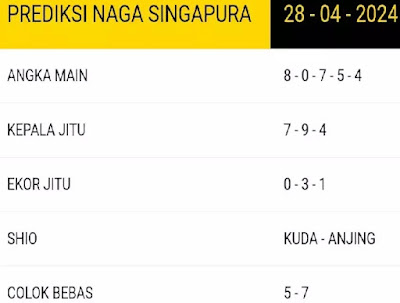
A. Angka Prediksi SGP hari ini 28 april 2024.
B. Prediksi sgp 28 4 2024.
C. Bocoran sgp 28 4 2024.
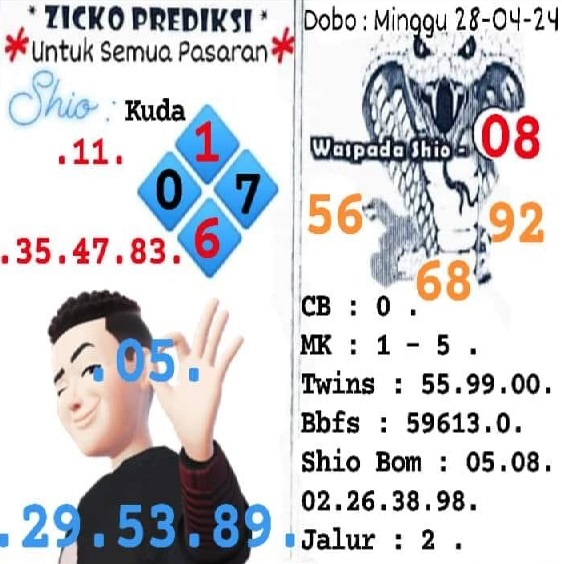
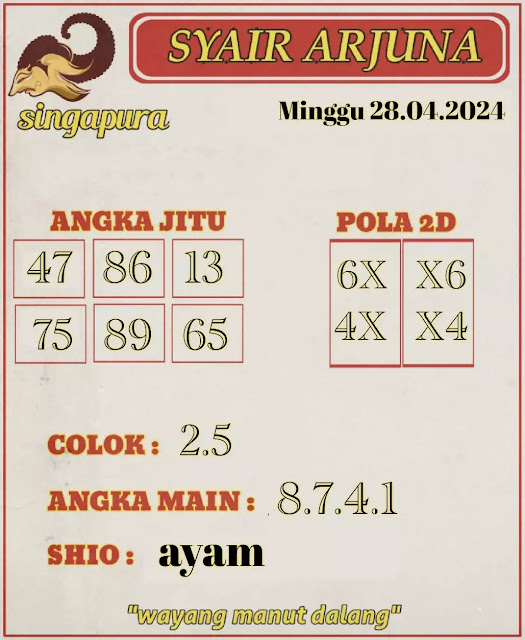
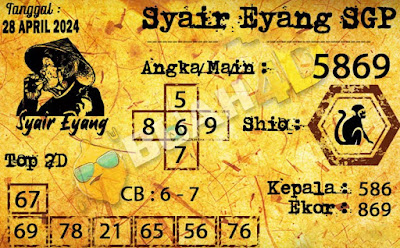
D. Forum syair sgp minggu 28 april 2024.
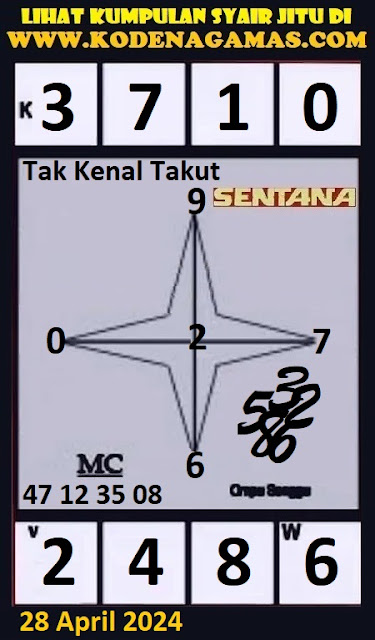
F. kode syair sgp 28 4 2024. Opesia SGP
Angka Main : 0623
Angka Ikut : 9584
Colok Makau : 62 / 95
Colok Bebas : 2 / 3
As : 062
Kop : 0
Kepala : 0/2
Ekor : 450
Pola 3D : 6xx / 2xx / 5xx
TOP JITU 2D :
09*05*08*04*69
65*68*64*29*25
28*24*39*35*34